
Nhóm AI của Nvidia bị cáo buộc đã sao chép video YouTube, Netflix trái phép
Samantha Cole của 404 Media mới đây đã báo cáo về việc Nvidia đã yêu cầu nhân viên tải xuống video từ YouTube, Netflix và các tập dữ liệu khác để phát triển các dự án AI thương mại cho riêng mình.
Nhà sản xuất card đồ họa có giá trị nhất, nhì thế giới này bị cho là đã sốt sắng trong việc chạy đua để khẳng định vị trí trong lĩnh vực trí tuệ nhân tạo. Giống như nhiều công ty công nghệ khác, họ đã áp dụng phương châm "hành động nhanh và phá vỡ mọi thứ", không loại trừ việc tìm kiếm nguồn dữ liệu để đào tạo AI theo nhiều cách khác nhau.
Nội dung đào tạo AI của Nvidia được cho là để phát triển mô hình cho các sản phẩm như 3D Omniverse (một nền tảng mở dựa trên Universal Scene Description (USD) giúp các cá nhân và doanh nghiệp hiện thực hóa ý tưởng 3D của mình dễ dàng hơn), hệ thống xe tự lái và các nỗ lực tạo ra “con người kỹ thuật số”.

Nvidia được cho là đã chỉ đạo nhân viên tải các video từ YouTune, Netflix và nhiều nguồn khác xuống để làm dữ liệu đào tạo AI.
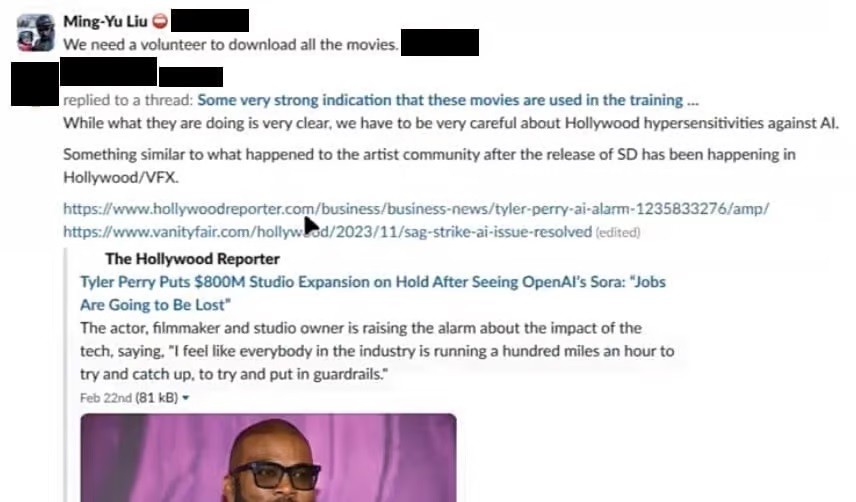
404 Media dẫn chứng, trong tin nhắn Slack (là một ứng dụng chat cho toàn bộ nhân viên trong một tổ chức) mà họ có được, một nhân viên Nvidia cũng đề xuất thu thập phim để làm dữ liệu. Lý do đưa ra là "Phim thực sự là nguồn dữ liệu tốt để có được sự nhất quán 3D giống như trò chơi và nội dung hư cấu nhưng chất lượng cao hơn nhiều".
Đáp lại, Ming-Yu Liu, Phó chủ tịch nghiên cứu tại Nvidia, trả lời: “Chúng tôi cần một người tình nguyện tải xuống tất cả các bộ phim”.
Các email mà 404 Media đã xem cho thấy các nhà quản lý dự án thảo luận về việc sử dụng 20 đến 30 máy ảo trên Amazon Web Services để tải xuống lượng video tương đương 80 năm mỗi ngày.
Liu cho biết trong một email vào tháng 5: "Chúng tôi đang hoàn thiện đường ống dữ liệu v1 và đảm bảo các tài nguyên điện toán cần thiết để xây dựng một kho dữ liệu video có thể tạo ra dữ liệu đào tạo tương đương với trải nghiệm hình ảnh trọn đời của con người mỗi ngày".
Trong các kênh Slack, nhân viên Nvidia cũng thảo luận về việc video nào của kênh YouTube nên được thu thập để đào tạo AI. Một nhà nghiên cứu đã đăng một số liên kết đến các kênh YouTube trong một kênh Slack và nói rằng: "Nếu bạn vẫn muốn nhận các đề xuất về các kênh YouTube mà chúng tôi có thể tải xuống, đây là một số kênh có thể thú vị để xem xét."
Trước thông tin được phát đi bởi 404 Media, Nvidia lập tức đã có phản hồi. Một phát ngôn viên của công ty cho biết, nghiên cứu của họ "hoàn toàn tuân thủ theo đúng văn bản và tinh thần của luật bản quyền" trong khi tuyên bố luật IP bảo vệ các biểu đạt cụ thể "nhưng không bảo vệ các sự kiện, ý tưởng, dữ liệu hoặc thông tin". Công ty coi hoạt động này tương đương với quyền của một người được "tìm hiểu các sự kiện, ý tưởng, dữ liệu hoặc thông tin từ một nguồn khác và sử dụng chúng để tạo ra biểu đạt của riêng họ".
YouTube dường như không đồng ý với điều này. Người phát ngôn Jack Malon đã phân tích vấn đề và trích dẫn lời CEO Neal Mohan nói với Bloomberg rằng, việc sử dụng YouTube để đào tạo các mô hình AI sẽ là "vi phạm rõ ràng" các điều khoản của công ty. "Bình luận trước đây của chúng tôi vẫn còn hiệu lực", Giám đốc Truyền thông chính sách của YouTube đã viết cho Engadget.
Nhiều nhân viên Nvidia không khỏi lo ngại về mặt đạo đức và pháp lý trước các diễn biến kể trên. Trước đó, các thông tin cho thấy, những quản lý của Nvidia đã thông báo cho nhân viên hoạt động này (tải video từ YouTube, Netflix xuống) đã được các cấp cao nhất của công ty bật đèn xanh. "Đây là quyết định của ban điều hành", Ming-Yu Liu, Phó Chủ tịch nghiên cứu tại Nvidia trả lời. "Chúng tôi có sự chấp thuận chung cho tất cả dữ liệu". Một số người khác tại công ty được cho là đã mô tả việc thu thập dữ liệu trên YouTube, Netflix là "vấn đề pháp lý mở" mà họ sẽ giải quyết trong tương lai.
Vụ việc khiến nhiều người liên tưởng tới phương châm cũ của Facebook (Meta) là "di chuyển nhanh và phá vỡ mọi thứ". Phương châm này đã thành công đáng ngưỡng mộ trong việc phá vỡ khá nhiều thứ, bao gồm cả quyền riêng tư của hàng triệu người.
Ngoài các video YouTube và Netflix, Nvidia được cho là đã hướng dẫn nhân viên đào tạo về cơ sở dữ liệu từ các đoạn giới thiệu phim trên MovieNet, các thư viện nội bộ về cảnh quay trò chơi điện tử và các tập dữ liệu video Github WebVid (hiện đã bị gỡ xuống sau khi ngừng hoạt động) và InternVid-10M. Tập dữ liệu sau chứa 10 triệu ID video YouTube.
Một số dữ liệu mà Nvidia được cho là đã đào tạo chỉ được đánh dấu là đủ điều kiện để sử dụng cho mục đích học thuật (hoặc phi thương mại). HD-VG-130M, một thư viện gồm 130 triệu video trên YouTube, bao gồm giấy phép sử dụng nêu rõ rằng nó chỉ dành cho mục đích nghiên cứu học thuật.
Minh Châu
Link nội dung: https://dothi.reatimes.vn/nhom-ai-cua-nvidia-bi-cao-buoc-da-sao-chep-video-youtube-netflix-trai-phep-5522.html