
Thú vị khi những mô hình AI hàng đầu cũng không đánh vần được từ "strawberry"
Chữ “r” xuất hiện nhiều lần trong từ “Strawberry” (dâu tây) đã làm khó các mô hình AI hàng đầu như GPT-4o của OpenAI, Claude của Anthropic. Vấn đề này không dễ khắc phục khiến cả các chuyên gia AI và người dùng không khỏi cảm thấy thú vị.
Các mô hình ngôn ngữ lớn (LLM) có thể viết bài luận và giải phương trình trong vài giây. Chúng có thể tổng hợp hàng terabyte dữ liệu nhanh hơn con người có thể mở một cuốn sách. Tuy nhiên, những AI có vẻ như toàn năng này đôi khi lại thất bại thảm hại đến mức sự cố trở thành một meme lan truyền.
Sự thất bại của các mô hình ngôn ngữ lớn trong việc hiểu các khái niệm về chữ cái và âm tiết chỉ ra một sự thật lớn hơn mà chúng ta thường quên: Những thứ này không có não. Chúng không suy nghĩ như chúng ta. Chúng không phải là con người, thậm chí không giống con người một cách đặc biệt.
Hầu hết các LLM đều được xây dựng trên transformers - một loại kiến trúc học sâu. Các mô hình transformer chia văn bản thành các token, có thể là các từ đầy đủ, âm tiết hoặc chữ cái, tùy thuộc vào mô hình.
“LLM dựa trên kiến trúc máy biến áp này, đáng chú ý là không thực sự đọc văn bản. Điều xảy ra khi bạn nhập lời nhắc là nó được dịch thành mã hóa”, Matthew Guzdial, một nhà nghiên cứu AI và là trợ lý giáo sư tại Đại học Alberta (Canada) cho biết. “Khi nó nhìn thấy từ 'the", nó có một mã hóa về ý nghĩa của "the", nhưng nó không biết về "T", "H", "E'”, chuyên gia này phân tích.
Điều này được cho là do các bộ biến đổi không thể tiếp nhận hoặc xuất ra văn bản thực tế một cách hiệu quả. Thay vào đó, văn bản được chuyển đổi thành các biểu diễn số của chính nó, sau đó được ngữ cảnh hóa để giúp AI đưa ra phản hồi hợp lý. Nói cách khác, AI có thể biết rằng các mã thông báo "straw" và "berry" tạo nên "strawberry", nhưng nó có thể không hiểu rằng "strawberry" bao gồm các chữ cái "s", "t", "r", "a", "w", "b", "e", "r", "r" và "y" theo thứ tự cụ thể đó. Do đó, nó không thể cho bạn biết có bao nhiêu chữ cái — chứ đừng nói đến bao nhiêu chữ "r" — xuất hiện trong từ "strawberry".
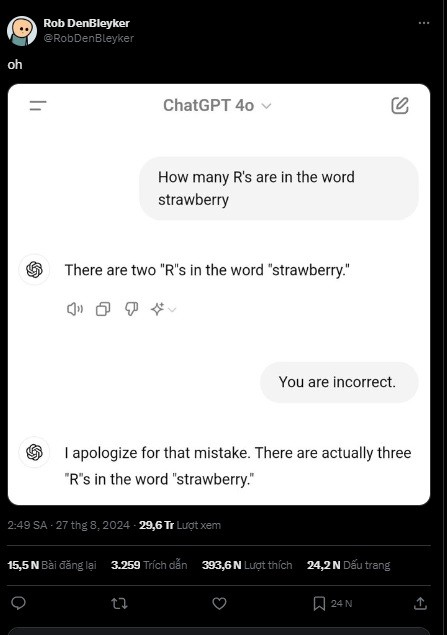
Điều đáng lưu ý là, vấn đề kể trên không dễ khắc phục vì nó nằm sâu trong chính kiến trúc giúp các LLM này hoạt động. Tháng trước, Kyle Wiggers của TechCrunch đã tìm hiểu sâu về vấn đề này và trao đổi với Sheridan Feucht, một nghiên cứu sinh tiến sĩ tại Đại học Northeastern chuyên ngành khả năng diễn giải LLM.
Feucht cho biết: "Thật khó để giải quyết câu hỏi về chính xác một "từ" là gì đối với một mô hình ngôn ngữ, và ngay cả khi chúng ta có được sự đồng ý của các chuyên gia về một vốn từ vựng hoàn hảo, các mô hình có lẽ vẫn thấy hữu ích khi "chia nhỏ" mọi thứ hơn nữa". "Tôi đoán rằng không có thứ gì gọi là một trình phân tích hoàn hảo do sự mơ hồ này".
Vấn đề này trở nên phức tạp hơn khi một LLM học nhiều ngôn ngữ hơn. Ví dụ, một số phương pháp phân chia có thể cho rằng một khoảng trắng trong câu sẽ luôn đứng trước một từ mới, nhưng nhiều ngôn ngữ như tiếng Trung, tiếng Nhật, tiếng Thái, tiếng Lào, tiếng Hàn, tiếng Khmer và các ngôn ngữ khác không sử dụng khoảng trắng để phân tách các từ. Nhà nghiên cứu AI của Google DeepMind Yennie Jun đã phát hiện ra trong một nghiên cứu năm 2023 rằng một số ngôn ngữ cần nhiều hơn tới 10 lần số lượng dấu hiệu so với tiếng Anh để truyền đạt cùng một ý nghĩa.
Feucht cho biết: "Có lẽ cách tốt nhất là để các mô hình xem trực tiếp các ký tự mà không áp dụng mã hóa, nhưng hiện tại, điều đó là không khả thi về mặt tính toán đối với các máy biến hình".
Các trình tạo hình ảnh như Midjourney và DALL-E không sử dụng kiến trúc biến áp nằm bên dưới các trình tạo văn bản như ChatGPT. Thay vào đó, các trình tạo hình ảnh thường sử dụng các mô hình khuếch tán, tái tạo hình ảnh từ nhiễu. Các mô hình khuếch tán được đào tạo trên các cơ sở dữ liệu hình ảnh lớn và chúng được khuyến khích cố gắng tái tạo thứ gì đó giống như những gì chúng học được từ dữ liệu đào tạo.
Asmelash Teka Hadgu, đồng sáng lập Lesan và là nghiên cứu viên tại Viện DAIR, nói với TechCrunch, “Các trình tạo hình ảnh có xu hướng hoạt động tốt hơn nhiều trên các hiện vật như ô tô và khuôn mặt con người, và kém hiệu quả hơn trên những thứ nhỏ hơn như ngón tay và chữ viết tay”.

Khi những meme về cách viết "strawberry" này tràn lan trên internet, OpenAI đang nghiên cứu một sản phẩm AI mới có tên mã là Strawberry, được cho là thậm chí còn thành thạo hơn trong việc suy luận. Sự phát triển của LLM đã bị hạn chế bởi thực tế là đơn giản là không có đủ dữ liệu đào tạo trên thế giới để làm cho các sản phẩm như ChatGPT chính xác hơn. Nhưng Strawberry được cho là có thể tạo ra dữ liệu tổng hợp chính xác để làm cho LLM của OpenAI thậm chí còn tốt hơn. Theo The Information, Strawberry có thể giải các câu đố chữ Connections của tờ New York Times, đòi hỏi tư duy sáng tạo và nhận dạng mẫu để giải và có thể giải các phương trình toán học mà nó chưa từng thấy trước đây.
Trong khi đó, Google DeepMind gần đây đã công bố AlphaProof và AlphaGeometry 2, các hệ thống AI được thiết kế cho lý luận toán học chính thức. Google cho biết hai hệ thống này đã giải được bốn trong số sáu bài toán từ Kỳ thi Olympic Toán quốc tế, đây là thành tích đủ tốt để giành huy chương bạc tại cuộc thi danh giá này.
Khá thú vị khi các meme về việc AI không thể đánh vần "dâu tây" lại được lan truyền cùng lúc với các báo cáo về Strawberry của OpenAI. Nhưng CEO của OpenAI, Sam Altman đã chớp lấy cơ hội để cho chúng ta thấy rằng ông đang có một sản phẩm đầy tiềm năng và đáng mong đợi trong ngành.
Minh Châu
Link nội dung: https://dothi.reatimes.vn/thu-vi-khi-nhung-mo-hinh-ai-hang-dau-cung-khong-danh-van-duoc-mot-tu-strawberry-6068.html