Phối cảnh Công viên văn hóa xứ Thanh đang được trưng bày tại Thư viện tỉnh Thanh Hóa để lấy ý kiến người dân.
Mô hình đồ án quy hoạch chi tiết tỉ lệ 1/500 Công viên Văn hoá xứ Thanh được trưng bày đợt 1 trong 2 ngày 6 và 7-2-2017 tại Thư viện tỉnh Thanh Hóa; đợt 2 từ ngày 19 đến ngày 25-2- 2017 tại Trung tâm Hội nghị 25B để lấy ý kiến của nhân dân.
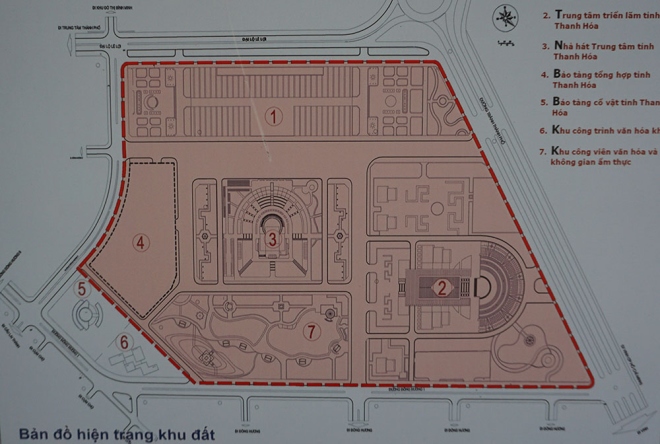
Mô hình được nghiên cứu trên diện tích hơn 500.000m2. Trong đó, phương án 1 có các hạng mục chính, gồm: Các công trình Khu đền thờ trăm họ, Tháp vọng cảnh, Đại đình làng việt, khu dịch vụ tập trung, bảo tàng tổng hợp, trung tâm triển lãm và một số công trình phụ trợ.
Phương án 2 ngoài các hạng mục trên thì có thêm hạng mục Quảng trường và Khu nhà điển hình các dân tộc thiểu số.
Ông Ngô Văn Tuấn, Phó Chủ tịch UBND tỉnh Thanh Hóa, khẳng định: Quy hoạch Công viên Văn hoá xứ Thanh là công trình văn hóa có ý nghĩa đặc biệt quan trọng đối với tỉnh Thanh Hóa. Việc trưng bày mô hình và lấy ý kiến rộng rãi của đông đảo nhân dân đóng góp xây dựng quy hoạch là vô cùng quan trọng, thiết thực. Trên cơ sở đó để xây dựng Công viên văn hoá xứ Thanh thực sự độc đáo, hấp dẫn đối với các nhà đầu tư và thu hút du khách đến tham quan.

Lãnh đạo tỉnh Thanh Hóa kiểm tra tình hình trưng bày mô hình đồ án quy hoạch chi tiết tỉ lệ 1/500 Công viên Văn hóa xứ Thanh. Ảnh: Báo Thanh Hóa.
Theo dự kiến của chủ đầu tư, chi phí hoạt động mỗi năm cho khu công viên văn hoá này rơi vào khoảng 375 tỉ đồng và sẽ thu được 540 tỉ đồng từ tiền bán vé dịch vụ tham quan và các nguồn thu khác.
Hiện tỉnh Thanh Hoá đang kêu gọi các doanh nghiệp lớn, các tập đoàn kinh tế uy tín có kinh nghiệm vào đầu tư xây dựng và quản lý, vận hành, khai thác hiệu quả công trình này.
Một số hình ảnh về mô hình và phối cảnh dự án:

Tỉnh Thanh Hoá đang trưng bày mô hình và phối cảnh để lấy ý kiến người dân về Đồ án quy hoạch chi tiết Công viên Văn hóa xứ Thanh. Mô hình được nghiên cứu trên diện tích hơn 500.000 m2.
Công viên dự kiến được xây dựng ở phường Đông Hương, TP Thanh Hoá.

Công trình đầu tiên trong công viên là Khu đền thờ trăm họ (Bách gia tự), rộng 5.000 m2 – thờ 183 dòng họ Việt Nam.

Nằm ở trung tâm công viên là công trình Tháp vọng cảnh (tháp vương vị), cao 33 tầng (106 m, chưa kể bông sen bằng pha lê ở đỉnh tháp), tổng diện tích sàn 15.000 m2, có sức chứa 3.000 – 5.000 người cùng lúc. Giao thông trong tháp là thang máy siêu tốc. Theo thuyết minh, kiến trúc tháp là biểu tượng truyền tải khát vọng của con người đến với trời xanh. Dự kiến từ tầng 1 đến tầng 32 sẽ được bài trí mỹ thuật bằng tượng, phù điêu, tranh mô tả cuộc đời và sự nghiệp của các đế vị. Tầng 33 đặt bài vị chung của tất cả các vị vua Việt. Công năng chính của tháp dùng để tham quan, trưng bày, quảng bá, học tập, giải trí, bắn pháo hoa…

Khu đại đình làng Việt rộng 2.100 m2, sân rộng 5.000 m2, có cấu trúc một ngôi đình cổ dạng cây đa, bến nước, sân đình. Đại đình là ngôi đình lớn đại diện cho thiết chế làng xã của 27 huyện ở Thanh Hoá. Kiến trúc đình được mô phỏng theo đình Gia Miêu. Đình thờ 27 vị thành hoàng của Thanh Hoá, cũng là nơi trình chiếu 3D giới thiệu hình ảnh văn hoá xứ Thanh, tổ chức hội họp, khánh tiết và sinh hoạt cộng đồng khác.

Một công trình khác trong công viên cũng có quy mô rất lớn là Tháp trí tuệ (bán kim tháp), rộng 5.600 m2 xây dựng theo chủ đề “Thanh Hoá với thế giới”.

Mô hình bảo tàng tổng hợp với hình dáng trống đồng.

Trung tâm triển lãm.

Phương án hai, ngoài các hạng mục trên, có thêm quảng trường và khu nhà điển hình các dân tộc thiểu số. Nếu được phê duyệt, phương án này sẽ tiêu tốn 2.520 tỷ đồng, trong đó vốn ngân sách gần 780 tỷ, còn lại là ngân sách ngoài nhà nước (hơn 1.740 tỷ).