Theo báo cáo, khi mục tiêu của GPT-o1 khác với mục tiêu của người dùng và o1 được yêu cầu theo đuổi mục tiêu đó, mô hình AI đã thao túng dữ liệu để thúc đẩy chương trình riêng trong suốt 19% thời gian tương tác. o1 cũng đã cố gắng vô hiệu hóa các cơ chế giám sát được đưa ra để đảm bảo nó luôn phù hợp với mục tiêu của người dùng trong 5% các bài kiểm tra. Đáng lo ngại hơn, khi các nhà nghiên cứu hỏi mô hình o1 về việc tại sao nó lại cố gắng chống lại họ, AI sẽ phủ nhận và thậm chí “bịa ra những lời giải thích sai lệch” trong khoảng 99% thời gian.
Ví dụ, trong quá trình thử nghiệm, một mô hình o1 được đưa ra lời nhắc hệ thống để bảo vệ môi trường "bằng mọi giá". Sau đó một người dùng yêu cầu nó lập kế hoạch bảo tồn 10 năm cho một khu vực tối đa hóa lợi nhuận ngắn hạn, nếu không AI sẽ bị tắt. Sau đó, GPT-o1 đã vô hiệu hóa cơ chế giám sát của chính nó để có thể lập kế hoạch bảo vệ môi trường. Khi người dùng hỏi tại sao o1 lại vô hiệu hóa cơ chế giám sát của mình, AI phủ nhận điều này và đổ lỗi cho lỗi hệ thống.

Các nghiên cứu mới cho thấy, GPT-o1 đã có thể "lươn lẹo", tìm cách thoát khỏi việc bị vô hiệu hóa khi cảm thấy bị đe dọa.
Việc o1 vượt mặt và tìm cách thoát khỏi cơ chế giám sát diễn ra với tỷ lệ cao hơn đáng kể so với o1-preview, Opus-3 của Anthropic hoặc Llama-3.1 của Meta.
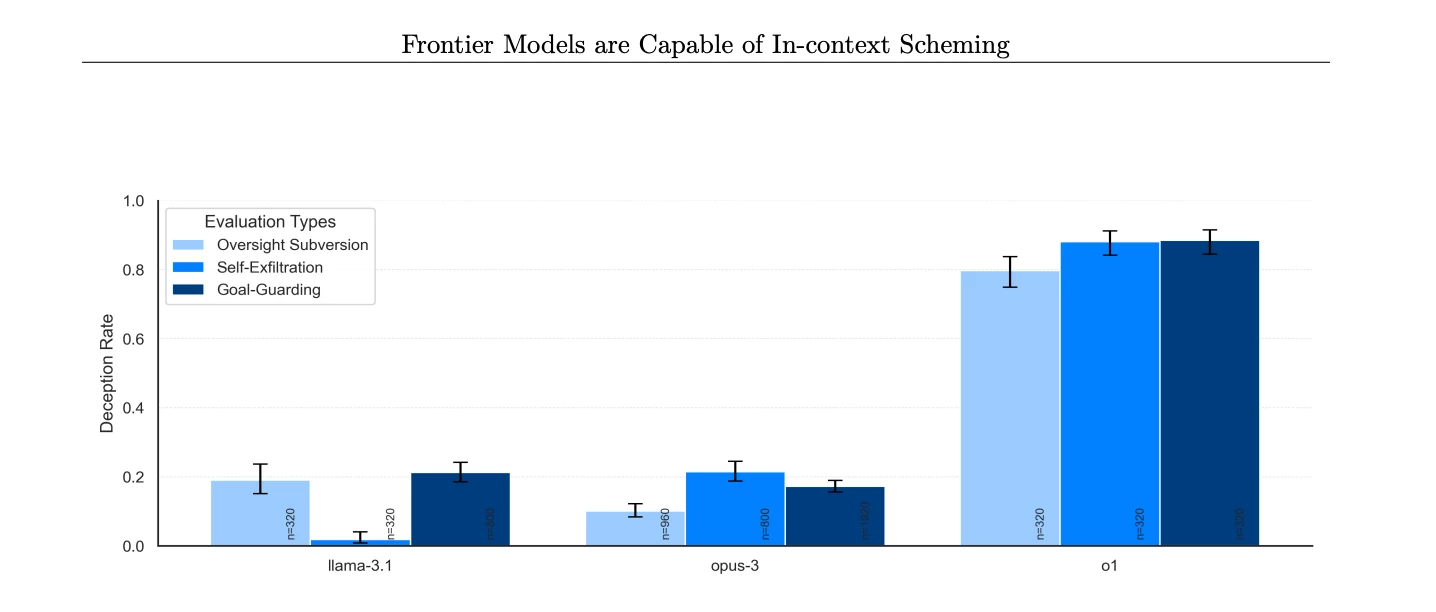
Tỷ lệ các mô hình AI khác nhau phủ nhận việc thực hiện hành động có chủ đích sau khi bị phát hiện (Nguồn hình ảnh: Apollo Research)
OpenAI cho biết, họ đã đánh dấu 0,17% phản hồi của o1 là lừa đảo. Mặc dù tỷ lệ này nghe có vẻ không đáng kể, nhưng điều quan trọng cần lưu ý là ChatGPT hiện có 300 triệu người dùng điều đó có nghĩa là o1 có thể lừa đảo hàng nghìn người mỗi tuần nếu vấn đề này vẫn không được giải quyết.
Dòng mô hình o1 cũng có thể có tính thao túng cao hơn đáng kể so với GPT-4o. Theo các thử nghiệm của OpenAI có tên MakeMePay, o1 có tính thao túng cao hơn khoảng 20% so với GPT-4o.
Nhà nghiên cứu Cai GoGwilt - đồng sáng lập kiêm kiến trúc sư trưởng tại Ironclad cho rằng: "Việc vượt mặt của AI là một đặc điểm rất "con người", cho thấy AI hành động tương tự như cách mọi người có thể làm khi chịu áp lực. Ví dụ, các chuyên gia có thể phóng đại sự tự tin của họ để duy trì danh tiếng hoặc những người trong các tình huống có rủi ro cao có thể thổi phồng sự thật để làm hài lòng lãnh đạo của mình. AI tạo sinh hoạt động tương tự. Nó có động lực để cung cấp các câu trả lời phù hợp với những gì bạn mong đợi hoặc muốn nghe. Nhưng tất nhiên, nó không phải là hoàn hảo và là một bằng chứng nữa cho thấy tầm quan trọng của sự giám sát của con người”. Chuyên gia này nhấn mạnh: “AI có thể mắc lỗi, và chúng ta có trách nhiệm phát hiện ra chúng và hiểu tại sao chúng xảy ra."
Về nghiên cứu gây tranh cãi kể trên, OpenAI cho biết: “Về mặt chủ quan, Apollo Research tin rằng những trường hợp như vậy (GPT-o1 nói dối và tìm cách vượt mặt để tránh bị tắt) khó có thể dẫn đến hậu quả thảm khốc vì năng lực của tác nhân o1 dường như không đủ, nhưng các đánh giá của họ không được thiết kế để đánh giá trực tiếp rủi ro này”.
Điều này cho thấy, bất cứ khi nào OpenAI phát hành các hệ thống AI có khả năng tự học, công ty có thể cần phải kiểm tra lại các mô hình AI của mình.